Learning about data; Working with quantitative data
In a previous blog, we described quantitative data as data that can be counted or measured in numerical values. A spreadsheet is a good basis for organising data ready for analysis. Now let us imagine you have some data to hand, this is how you might want to try and use it.
Ways to analyse quantitative data.
Example 1: Looking at what the data tells you itself.
We generally start with calculating averages to consider the range of data (the highest score and the lowest score collected). If we consider 2 sets of data (Data set A and Data set B):
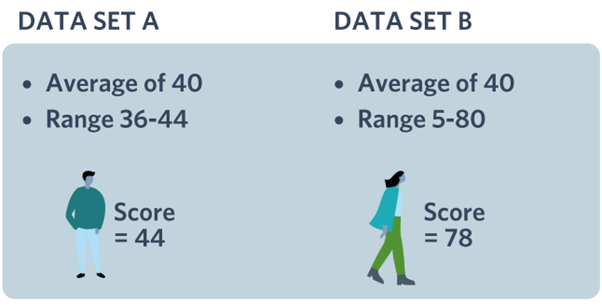
From Data Set A, it is apparent that a similar experience was shared by the large majority of the audience because the average score is 40, but the range is from 36-44. That means the lowest answer was 36, which is quite close to 40 and the highest was 44 which is still quite close to 40.
However, in Data Set B, there was a much wider range of experience. This should be questioned as to why experiences are so varied, illustrated by the wide range in the data. Why did some individuals have such a higher score than others? Did some people have a different tutor, or venue, or have more time? There are many reasons why the range could be so high.
Example 2: Comparing data to other national data available.
Another possible way to compare data could be as in the worked example below where the Warwick Edinburgh Scale of Wellbeing was used to measure participant wellbeing.
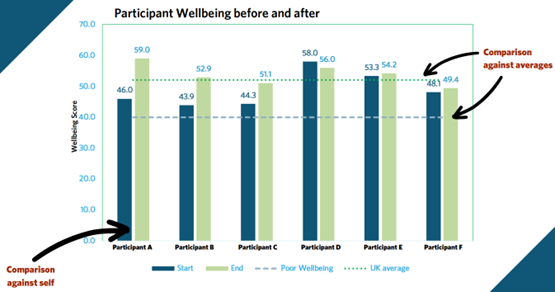
Participants scores were collected over a period of time, firstly at the start of their engagement and then, at the end. This graph represents a comparison in:
- Each individual’s wellbeing from the start versus at the end. This is often a reflection of the impact of their engagement.
- The individuals’ wellbeing who took part versus the national average
- The individuals’ wellbeing score versus the NHS score of 40 which is believed to be indicative of poor wellbeing.
- The individuals’ wellbeing versus one another.
Using quantitative data to help with forecasting & future decision making
Using percentages makes making comparisons easier to relate to and understand.
We use an example of a cinema and record audience attendance numbers of time. Attendance could be affected by the popularity of the content of the film, seasonal trends or weather. The trend line shows the overall audience is growing and then this line can be used to forecast on at the same trajectory. This will help you to identify if you are likely to achieve your audience targets.
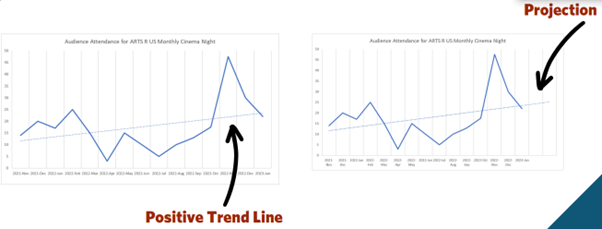
This information can also help you to make decisions about your capacity too and streamline your resources. For example, if you were thinking about moving a cinema location to a larger space, it would be worth looking at the trend line to think about venue size. If you were looking at two venues and one had a capacity of 100, and another 200, you might want to look at what your predicted audience size would be in six months’ time and negotiate the lease or hire accordingly. This is an example of making a data-driven-decision, something we are passionate about at The Evaluator.
Taking notice of negative space in data
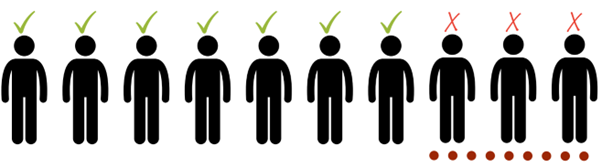
It’s important to take note of the 70% who are agreeing but also to take note of the 30% who are disagreeing and find out why this is the case. It is worth delving a bit deeper into on the minority and finding out what was the cause of their response.
At The Evaluator, we tend to represent 3 answers ‘yes’, ‘no’ and ‘prefer not to say’ in our reporting. If there’s a high number who indicate that they would ‘prefer not to say’ then it would be suggested they might insecure about completing the survey. Often their indecision is explained in their qualitative answers and this is worth taking note of when creating future surveys.
Dealing with ‘satisficing’ survey responses.
This is the term we use when people respond with the answers that they think you are looking for and may not read all the questions. An indication of satisficing is when respondents repeatedly choose 3 when presented with a 1-5 scale. We don’t come across these very often, as we spend a lot of time making sure our surveys are easy to complete, and varied, but if we do spot them, we will try and remove these answers from our data analysis. It’s important to encourage honesty in answering survey questions.
A final tip
All data can be segmented but you do need to think about the time you have to spend on this as it is time consuming. In segmentation ideally you are looking for what is more than 10% different to the average. In the example of the graph below, it is worth looking at segmenting to see the results demographics of the areas that are 10% above and 10% below the average line.