What are the Indices of Multiple Deprivation?
What are the Indices of Multiple Deprivation?
If you have ever read one of our reports, you’ll likely see reference to something called the Indices of Multiple Deprivation, or ‘IMD’.
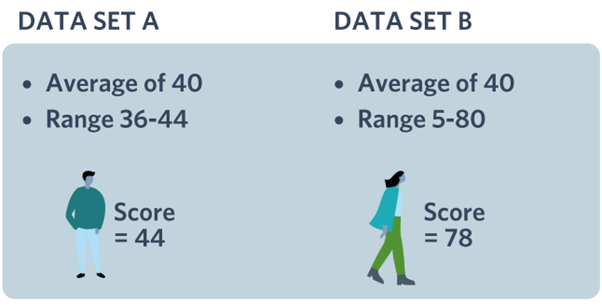
We use the IMD as a powerful tool to analyse and understand the barriers and socio-economic status of audiences, participants, and volunteers. We use postcodes to measure the IMD status, and this means that people find it easy to answer. This does mean that we are looking at the household status too.
The results give our clients an idea of which people they are attracting to their projects and what barriers they may be facing in life.
Statistically, people who live within areas of greater deprivation have more barriers in their lives and are less likely to engage with the arts and nature and are more likely to have greater issues with their wellbeing. That’s one of the reasons funders do like to understand if projects and organisations are reaching people from the most deprived areas.
How are the indices of multiple deprivation worked out?
The IMD is worked out using a range of factors which are assessed across the UK and given a score. The factors are listed below:
- Income deprivation: how many people in the area are experiencing low-income levels.
- Employment deprivation: what is the rate of unemployment in the area?
- Education deprivation: what are the average qualifications within the area, and how easy is it to access quality education?
- Health deprivation and disability: what is the average life expectancy and disability prevalence in the area?
- Crime: how much crime occurs within the area
- Housing deprivation: how affordable is housing within the area, and are there other barriers to people accessing housing
- Living environment: what is the air quality like in the area, and are there green spaces?
These scores are compiled to give a ranking, which are then categorised into ten deciles. The entirety of England falls equally into one of ten deciles, with decile 1 indicating the most deprivation, and area 10 having the least deprivation.
If you were targeting deprived areas, you might want to reach 50% of people living in IMD1 and 2 for example. Or if you wanted a perfect section of the UK represented in your project, you might want to see 10% of your audience from each decile.
We think the IMD is a useful tool and aim to use it in every evaluation where relevant.